There are plenty of analytics problems in the forestry space that require a good algorithm or optimization to figure out. Truck routing, harvest scheduling, growth and yield forecasting, the list goes on.
The algorithms themselves are important, but the data being fed into them is even more important. Not only does the quality of the data itself directly influence the outcome of the algorithm, but depending on the nature of the algorithm, any problems in the data may be exploited by the algorithm.
A road that’s listed as 100 km shorter than it actually is will get a lot of trucks routed through it. A seedling type whose growth rate is missing a decimal point will likely get planted everywhere.
Algorithms and optimizations are great for finding the best solution to problems, but they are even better at finding problems in your data.
Sometimes.
This is an insidious problem because everything usually looks like it’s working fine. There are no error messages, no scary crashes, no walls of command line text, just an algorithm that delivers a solution. That solution might even look better than you expected too.
But a big problem is lurking under the surface (cue Jaws theme).
Buried somewhere is a mistake. Something that gives the algorithm an advantageous, yet inaccurate view of reality. These are the kinds of problems that are only found through careful examination of the results. Interrogation of your algorithm outputs is critical in these situations and any discrepancies in the output should be traced back to issues in the input.
I encountered an interesting instance of this recently, while working on a road routing tool. This tool takes layers like a DEM, watercourses, wetlands and finds the lowest cost places to build a road (by avoiding things like steep terrain, stream crossing (bridges and culverts) and ecological sensitivities). The objective is to reach target operating areas while building as little road as possible, and while keeping the cost of that road as low as possible (Both from an economic and environmental standpoint).
The tool was producing results as expected, but upon closer examination I discovered this:
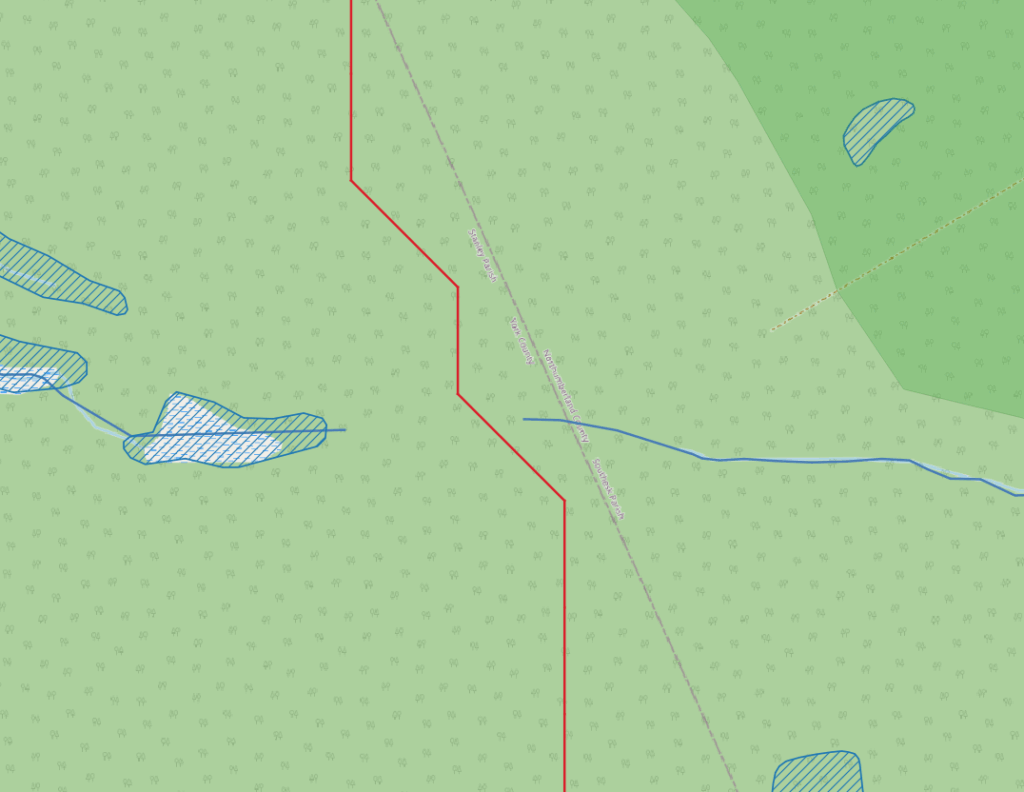
You can see the planned road (in red) moving through a suspicious gap in the watercourse layer (in blue). That could be the point between two watersheds (The tool might have been following a ridge line), but it looked suspicious to me.
Now this is exactly what you would expect this particular algorithm to do. It naturally wants to avoid crossing watercourses unless absolutely necessary, and the data fed into the tool will encourage it to do so. However, the basic assumption is that that data is accurate. All the data says is where a watercourse is or isn’t.
If we look at the DEM in this area, we can see there is clearly some kind of stream in that section.
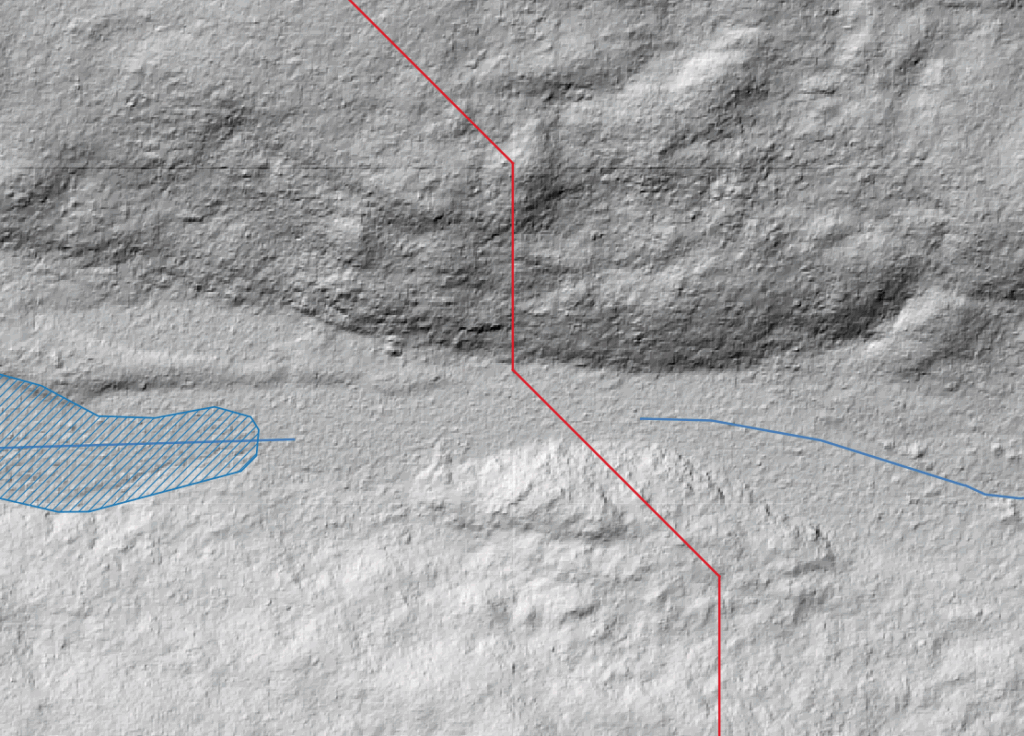
If not a stream then possibly some kind of wetland, but definitely not a ridge or other terrain feature that would lead to a realistic break in the stream layer. Note that in this case I’m only using the DEM for slope and elevation related data, not for detecting streams, that’s done entirely off of the vector layer.
This tells us a couple of important things: First, the algorithm is working as intended. It did pick the cheapest place to route that road, and second, we can’t trust the result because the input data is suspect.
An algorithm like this will exploit these sorts of loopholes all the time. The quality of the input data is critical. Taking an output like this and implementing it in reality requires ground truthing and further assessment to catch issues like this. Ideally, any reality discovered through that process should be fed back to re-run the algorithm. There could be a cascade of decisions made by the algorithm based on this one hole in the data. Plug that hole, and the best result might be very different.
Now while these problems can be hard to find (and even harder to fix) there is a silver lining. Exploiting gaps in data means an algorithm is doing what we want it to do. It is a sign of bad data, but a well executed algorithm. Even perfectly correct and accurate data is going to have opportunities and we want algorithms to find those (legitimate) opportunities.